Note
Click here to download the full example code
Community and Crime¶
This is a real dataset of per capita violent crime, with demographic data comprising 128 attributes from 1994 counties in the US.
The original dataset can be found here: http://archive.ics.uci.edu/ml/datasets/Communities+and+Crime
The target variables (per capita violent crime) are normalized to lie in a [0, 1] range. We preprocessed this dataset to exclude attributes with missing values.
# Author: Vinicius Marques <vini.type@gmail.com>
# License: MIT
Imports
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from pyglmnet import GLM, GLMCV, datasets
Download and preprocess data files
X, y = datasets.fetch_community_crime_data()
n_samples, n_features = X.shape
Out:
...0%, 0 MB
...0%, 0 MB
...1%, 0 MB
...2%, 0 MB
...2%, 0 MB
...3%, 0 MB
...4%, 0 MB
...5%, 0 MB
...5%, 0 MB
...6%, 0 MB
...7%, 0 MB
...8%, 0 MB
...8%, 0 MB
...9%, 0 MB
...10%, 0 MB
...11%, 0 MB
...11%, 0 MB
...12%, 0 MB
...13%, 0 MB
...14%, 0 MB
...14%, 0 MB
...15%, 0 MB
...16%, 0 MB
...17%, 0 MB
...17%, 0 MB
...18%, 0 MB
...19%, 0 MB
...20%, 0 MB
...20%, 0 MB
...21%, 0 MB
...22%, 0 MB
...23%, 0 MB
...23%, 0 MB
...24%, 0 MB
...25%, 0 MB
...25%, 0 MB
...26%, 0 MB
...27%, 0 MB
...28%, 0 MB
...28%, 0 MB
...29%, 0 MB
...30%, 0 MB
...31%, 0 MB
...31%, 0 MB
...32%, 0 MB
...33%, 0 MB
...34%, 0 MB
...34%, 0 MB
...35%, 0 MB
...36%, 0 MB
...37%, 0 MB
...37%, 0 MB
...38%, 0 MB
...39%, 0 MB
...40%, 0 MB
...40%, 0 MB
...41%, 0 MB
...42%, 0 MB
...43%, 0 MB
...43%, 0 MB
...44%, 0 MB
...45%, 0 MB
...46%, 0 MB
...46%, 0 MB
...47%, 0 MB
...48%, 0 MB
...49%, 0 MB
...49%, 0 MB
...50%, 0 MB
...51%, 0 MB
...51%, 0 MB
...52%, 0 MB
...53%, 0 MB
...54%, 0 MB
...54%, 0 MB
...55%, 0 MB
...56%, 0 MB
...57%, 0 MB
...57%, 0 MB
...58%, 0 MB
...59%, 0 MB
...60%, 0 MB
...60%, 0 MB
...61%, 0 MB
...62%, 0 MB
...63%, 0 MB
...63%, 0 MB
...64%, 0 MB
...65%, 0 MB
...66%, 0 MB
...66%, 0 MB
...67%, 0 MB
...68%, 0 MB
...69%, 0 MB
...69%, 0 MB
...70%, 0 MB
...71%, 0 MB
...72%, 0 MB
...72%, 0 MB
...73%, 0 MB
...74%, 0 MB
...75%, 0 MB
...75%, 0 MB
...76%, 0 MB
...77%, 0 MB
...77%, 0 MB
...78%, 0 MB
...79%, 0 MB
...80%, 0 MB
...80%, 0 MB
...81%, 0 MB
...82%, 0 MB
...83%, 0 MB
...83%, 0 MB
...84%, 0 MB
...85%, 0 MB
...86%, 0 MB
...86%, 0 MB
...87%, 0 MB
...88%, 0 MB
...89%, 0 MB
...89%, 0 MB
...90%, 0 MB
...91%, 0 MB
...92%, 0 MB
...92%, 0 MB
...93%, 0 MB
...94%, 0 MB
...95%, 1 MB
...95%, 1 MB
...96%, 1 MB
...97%, 1 MB
...98%, 1 MB
...98%, 1 MB
...99%, 1 MB
...100%, 1 MB
Split the data into training and test sets
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.33, random_state=0)
Fit a binomial distributed GLM with elastic net regularization
# use the default value for reg_lambda
glm = GLMCV(distr='binomial', alpha=0.05, score_metric='pseudo_R2', cv=3,
tol=1e-4)
# fit model
glm.fit(X_train, y_train)
# score the test set prediction
y_test_hat = glm.predict_proba(X_test)
print("test set pseudo $R^2$ = %f" % glm.score(X_test, y_test))
Out:
test set pseudo $R^2$ = 0.161891
Now use GridSearchCV to compare
import numpy as np # noqa
from sklearn.model_selection import GridSearchCV # noqa
from sklearn.model_selection import KFold # noqa
cv = KFold(3)
reg_lambda = np.logspace(np.log(0.5), np.log(0.01), 10,
base=np.exp(1))
param_grid = [{'reg_lambda': reg_lambda}]
glm = GLM(distr='binomial', alpha=0.05, score_metric='pseudo_R2',
learning_rate=0.1, tol=1e-4, verbose=True)
glmcv = GridSearchCV(glm, param_grid, cv=cv)
glmcv.fit(X_train, y_train)
print("test set pseudo $R^2$ = %f" % glmcv.score(X_test, y_test))
Out:
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
/Users/mainak/Documents/github_repos/pyglmnet/pyglmnet/pyglmnet.py:864: UserWarning: Reached max number of iterations without convergence.
"Reached max number of iterations without convergence.")
test set pseudo $R^2$ = 0.153298
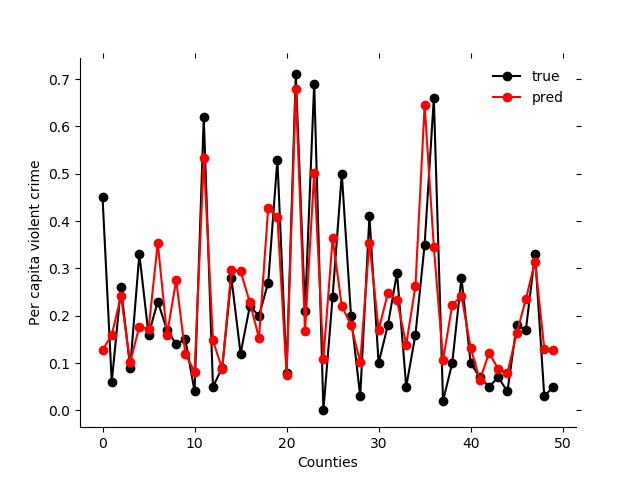
Plot the true and predicted test set target values
plt.plot(y_test[:50], 'ko-')
plt.plot(y_test_hat[:50], 'ro-')
plt.legend(['true', 'pred'], frameon=False)
plt.xlabel('Counties')
plt.ylabel('Per capita violent crime')
plt.tick_params(axis='y', right='off')
plt.tick_params(axis='x', top='off')
ax = plt.gca()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()
Out:
/Users/mainak/Documents/github_repos/pyglmnet/examples/plot_community_crime.py:90: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
Total running time of the script: ( 0 minutes 13.932 seconds)